“社会对人们始终有一种仇视的敌意,不相信任何一个人,更不同情任何一个人。爱钱如命的悭吝,还是心理变态上的次要现象。相反的,有器度、有见识的人,他虽然从艰苦困难中成长,反而更具有同情心和慷慨好义的胸襟怀抱。因为他懂得人生,知道世情的甘苦。”
——南怀瑾

第二章 C++基础
PART I 变量和基本类型
1.算术类型P32
在书中我总结了以下容易忽略的类型:
|
wchart |
宽字符 | 16 位 |
|
char16t |
Unicode 字符 |
16 位 |
|
char32t |
Unicode字符 |
32 位 |
|
long |
长整型 |
32位 |
|
long long |
长整型 | 64位 |
|
float |
单精度浮点数 |
6 位有效数字 |
| double | 双精度浮点数 |
10位有效数字 |
| long double | 扩展精度浮点数 |
10位有效数字 |
注意事项如下:
- 当我们把一个整数值赋给浮点类型时,小数部分记为0。如果该整数所占的空间超过了浮点类型的容量,精度可能有损失。
- 当我们赋给无符号类型一个超出它表示范围的值时,结果是初始值对无符号类型表示数值总数取模后的余数。例如,256比特大小的unsigned char 可以表示0至255区间内的值,如果我们赋了一个区间以外的值,则实际的结果是该值对 256取模后所得的余数。因此,把-1 赋给 8 比特大小的unsigned char 所得的结果是255。
- 当我们赋给带符号类型一个超出它表示范围的值时,结果是未定义的(undefined)。此时,程序可能继续工作、可能崩溃,也可能生成垃圾数据。
无符号类型使用会产生着严重的问题,在这里我举例说明无符号类型遇见内存溢出时的结果:
Eg1:
1. unsigned u = 10; 2. int i = -42; 3. std::cout << i + i << std::endl; // 输出-84 4. std::cout << u + i << std::endl;// 如果int占32位,输出4294967264
请大家思索下面这个例子输出各为什么:
Eg2:
-
for (int i = 10; i >= 0; --i) -
{ -
std::cout << i << std::endl; -
} -
for (unsigned i = 10; i >= 0; --i) -
{ -
std::cout << i << std::endl; -
} -
unsigned u = 11; -
while( u > 0) -
{ -
--u; -
std::cout << u << std::endl; -
}
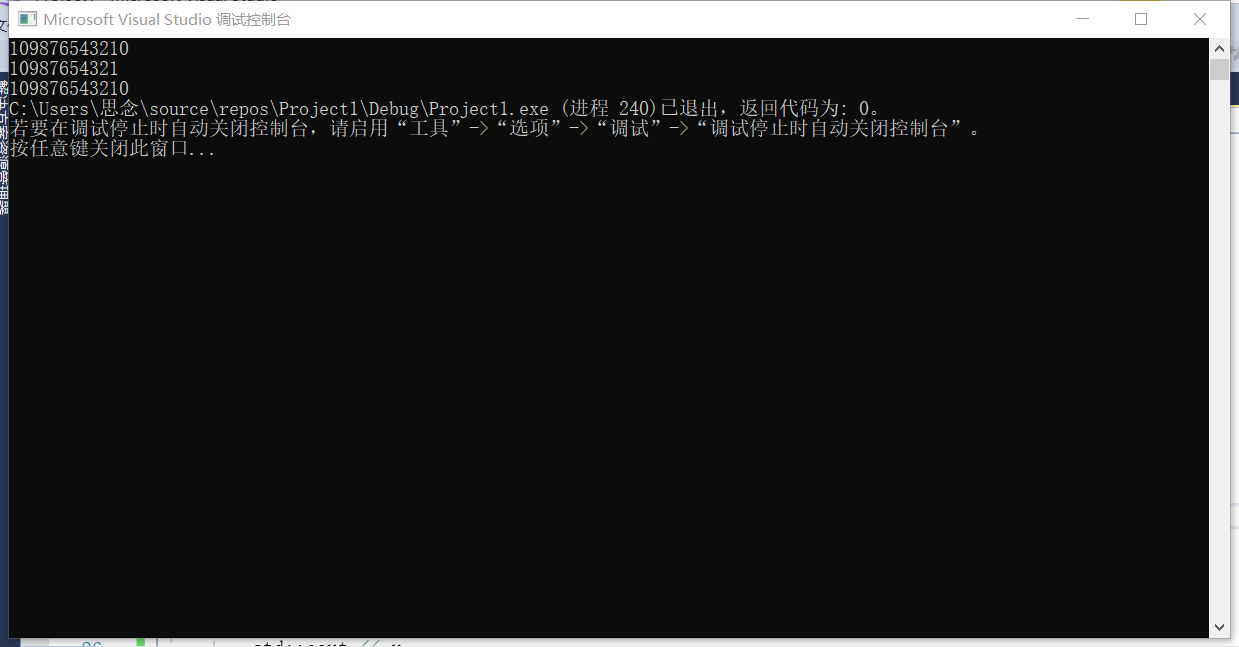
可见第二个for循环的输出是无限制的,因为i根本不可能<0,不满足for的条件,若将第二个for循环改为:
-
for(unsigned i = 10; i > 0; --i) -
{ -
std::cout << i << std::endl; -
}
我们可以得到结果如下:
2.字符串P_36
编译器在每个字符串的结尾处添加一个空字符“/0”,因此,字符串字面值的实际长度要比它的内容多1。
接下来我们重点学习转义序列,它是一种在字符串和字符字面值中使用的特殊字符组合,用于表示一些不可打印字符、特殊字符或者编码字符。以下是一些常见的转义序列:
|
控制字符 |
转义字符 | 数值转义序列 |
|
\a:响铃(警告声) |
\':单引号 |
\0:空字符 |
|
\b:退格(后退) |
\":双引号 |
ooo:八进制值(其中 ooo 是 1-3 个八进制数字) |
|
\f:换页 |
\\:反斜杠 |
\xhh:十六进制值(其中 hh 是 1-2 个十六进制数字) |
|
\n:换行 |
\?:问号 |
|
|
\r:回车 |
Unicode 转义序列:
|
|
|
\t:制表符 |
\uXXXX:表示 16 位 Unicode 字符(其中 XXXX 是 4 个十六进制数字) |
|
| \v:纵向制表符 | \UXXXXXXXX:表示 32 位 Unicode 字符(其中 XXXXXXXX 是 8 个十六进制数字) |
|
这些转义序列允许你在字符串和字符字面值中表示一些特殊字符或不可打印的字符。
3.初始化P_39
对象初始化的注意事项如下:
- 初始化不是赋值,初始化的含义是创建变量时赋予其一个初始值,而赋值的含义是把对象的当前值擦除,而以一个新值来替代。
- 定义于函数体内的内置类型的对象如果没有初始化,则其值未定义。类的对象如果没有显式地初始化,则其值由类确定。
- 建议初始化每一个内置类型的变量。虽然并非必须这么做,但如果我们不能确保初始化后程序安全,那么这么做不失为一种简单可靠的方法。
4.声明变量与定义变量P_41
为了支持分离式编译,C++语言将声明和定义区分开来。声明(declaration)使得名字为程序所知,一个文件如果想使用别处定义的名字则必须包含对那个名字的声明。而定义(definition)负责创建与名字关联的实体(定义还会申请存储空间)。
如果想声明一个变量而非定义它,就在变量名前添加关键字extern,而且不要显式地初始化变量:
Eg3:
-
extern int i; //声明而非定义 -
int j; //声明并定义 -
//变量能且只能被定义一次,但是可以被多次声明。
5.变量引用P_45
引用并非对象,相反的,它只是为一个已经存在的对象所起的另外一个名字,引用不能指向为一个常数且不能在不同类型之间进行,请思考如下实例的输出是什么?
Eg4:
-
int main() { -
int a = 10; -
int &b = a; -
a++; -
cout << b << endl; -
b++; -
cout << a << endl; -
return 0; -
}
void*指针:
void*是一种特殊的指针类型,可用于存放任意对象的地址。一个 void*指针存放着一个地址,这一点和其他指针类似。不同的是,我们对该地址中到底是个什么类型的对象并不了解:
Eg5:
doubleobj=3.14,*pd= &obj;// 正确,void*能存放任意类型对象的地址void*pv=&obj;// obi可以是任意类型的对象pv=pd;// pv可以存放任意类型的指针
6.指针P_47
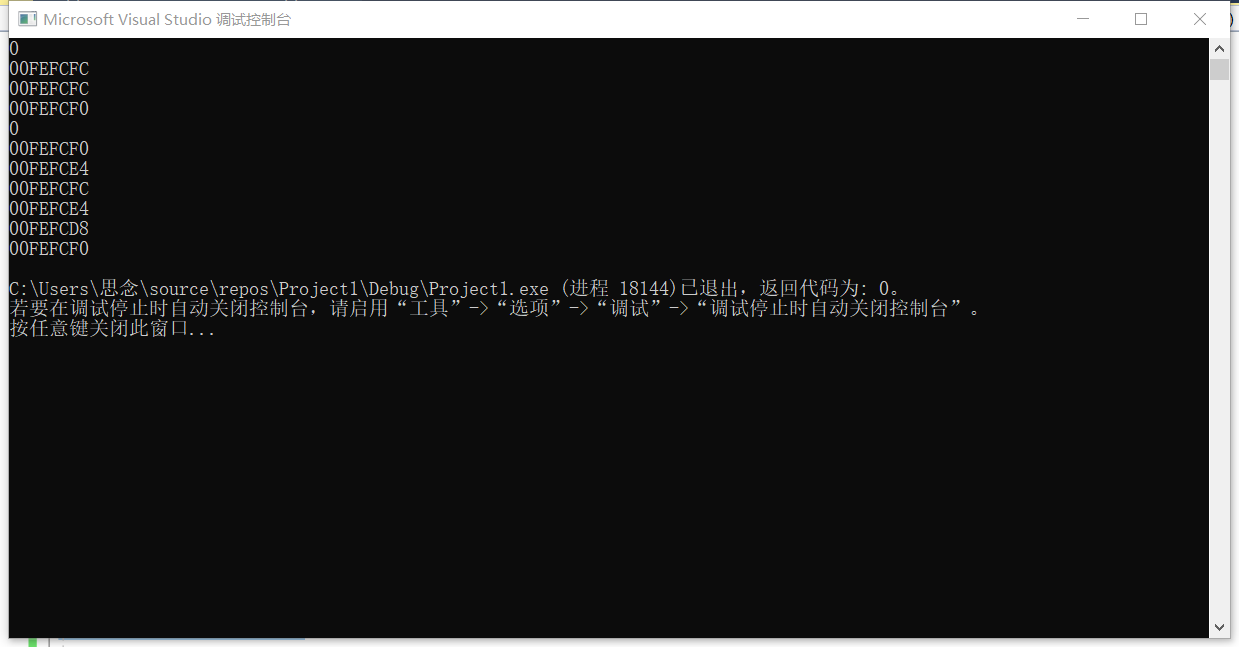
指针的学习与使用一直是重点与难点,笔者在这里并不觉得很困难,笔者着重列出了一个程序,若读者真正掌握了指针的内核,下面的Eg6也只是小菜一碟罢了,希望读者先进行思考以后再观察答案。
Eg6:
-
inta = 0; -
int*b = &a; -
int**c = &b; -
int***d = &c; -
cout << a << endl; -
cout << &a << endl; -
cout << b << endl; -
cout << &b << endl; -
cout << *b << endl; -
cout << c << endl; -
cout << &c << endl; -
cout << *c << endl; -
cout << d << endl; -
cout << &d << endl; -
cout << *d << endl;
7.顶层constP_53
顶层 const(top-level const)表示指针本身是个常量,而用名词底层const (low-level const)表示指针所指的对象是一个常量,指针类型既可以是顶层 const 也可以是底层 const,这一点和其他类型相比区别明显:
顶层 const: 如果一个变量被声明为顶层 const,那么该变量本身是不可修改的,但是它所指向的对象可以修改。
Eg7:
-
const int x = 10; // x 是顶层 const,不能修改 x 的值 -
int y = 20; -
const int* ptr = &y; // ptr 是指向常量的指针,不能通过 ptr 修改 y 的值,但可以通过其他途径修改 y 的值
底层 const: 如果一个变量被声明为底层 const,那么该变量所指向的对象是不可修改的。
Eg8:
-
int a = 5; -
constint* ptr1 = &a; // ptr1 是底层 const,不能通过 ptr1 修改 a 的值,但可以通过其他途径修改 a 的值 -
intconst* ptr2 = &a; // 与上面的语句等价
当执行对象的拷贝操作时,常量是顶层const 还是底层const 区别明显。其中,顶层const不受什么影响。
另一方面,底层 const 的限制却不能忽视。当执行对象的拷贝操作时,拷入和拷出的对象必须具有相同的底层 const 资格,或者两个对象的数据类型必须能够转换。一般来说,非常量可以转换成常量,反之则不行。
Eg9:
-
class Base { -
public: -
void nonConstFunction() { -
// 修改成员变量 -
data = 10; -
} -
void constFunction() const { -
// 不允许修改成员变量,但可以读取 -
int value = data; -
} -
private: -
int data = 0; -
}; -
class Derived : public Base { -
// ... -
}; -
int main() { -
const Base baseObj; // 常量 Base 对象 -
Base nonConstBaseObj; // 非常量Base 对象 -
// 下面的操作是不允许的,因为nonConstFunction() 修改了 data,但 baseObj 是常量对象 -
// baseObj.nonConstFunction(); // 错误! -
// 下面的操作是允许的,因为constFunction() 不修改 data,而且 baseObj 是常量对象 -
constFunction(); // OK -
// 拷贝构造函数,涉及到拷贝常量对象到非常量对象 -
nonConstBaseObj = baseObj; // 错误!拷贝操作需要底层const 保持一致 -
return 0; -
}
在上述示例中,baseObj 是一个常量 Base 对象,因此不能调用非常量成员函数来修改其成员变量。此外,当我们试图将一个常量对象 baseObj 拷贝到一个非常量对象 nonConstBaseObj 时,编译器会报错,因为拷贝操作需要拷贝和目标对象具有相同的底层 const 限制。
8.类型别名autoP_61
以下是auto的一些关键点:
- 类型推导: 当使用 auto 声明变量时,编译器会根据变量的初始化表达式推导出变量的类型。这意味着你不必显式指定变量的类型,编译器会在编译时自动完成这项工作。
- 简化代码: auto 可以使代码更简洁,特别是在涉及复杂类型的场景中,如模板、迭代器和函数返回值类型等。
- 与模板一起使用: 在模板编程中,auto 可以用于处理泛型类型,以避免显式指定模板参数类型。
Eg10:
-
auto x = 5; // x 的类型将被推导为int -
auto y = 3.14; // y 的类型将被推导为double -
auto str = "Hello, World!"; // str 的类型将被推导为const char* -
auto vec = std::vector<int>{1, 2, 3}; // vec 的类型将被推导为std::vector<int> -
std::vector<int> numbers = {10, 20, 30, 40}; -
for(auto it = numbers.begin(); it != numbers.end(); ++it) { -
// 使用 auto 让迭代器的类型由编译器推导 -
std::cout << *it << " "; -
}
值得注意的是:
- auto 推导的类型是在编译时确定的,因此它并不会引入运行时开销。
- 在某些情况下,使用 auto 可能会减少代码的可读性,特别是当初始化表达式复杂或不明确时。
- auto 并不适用于那些无法从初始化表达式中明确推导出类型的情况。
- 在使用 auto 时,要权衡代码的简洁性和可读性,确保使用 auto 不会引入不必要的混淆或歧义。
auto与顶层const的关系:
会自动忽略顶层const,但是保留底层const。
9. decltypeP_63
- 类型推导: decltype 从表达式中提取类型信息,而不会实际计算表达式的值。这使得你可以在不执行代码的情况下获取表达式的类型。
- 变量类型声明: 你可以使用 decltype 来声明一个变量,该变量的类型与给定表达式的类型相同。
Eg11:
-
int x = 5; -
decltype(x) y; // y 的类型将会是int
- 函数返回类型: decltype 可以用于推导函数的返回类型,特别是在模板编程中非常有用,可以根据函数返回值进行类型匹配。
Eg12:
-
int add(int a, int b) { -
return a + b; -
} -
decltype(add(1, 2)) result; // result 的类型将会是int
- 表达式类型推导: 你可以使用 decltype 推导一个表达式的类型,而不仅仅是一个变量的类型。
Eg13:
-
int x = 5; -
int y = 10; -
decltype(x + y) z; // z 的类型将会是int,因为 x + y 是一个表达式
- 引用和 const 保留: decltype 会保留引用和 const 修饰符。
Eg14:
-
const int x = 5; -
decltype(x) y = 10; // y 的类型将会是const int
- 表达式不会被执行: decltype 不会执行表达式,它只是分析表达式的类型。这意味着如果你有一个可能在运行时产生副作用的表达式,decltype 不会触发这些副作用。
2023年8月24日
NHG:)


文章评论