本文最后更新于 2025-03-25T20:48:30+08:00
页表
页表是操作系统用来管理虚拟内存的数据结构。页表将虚拟地址映射到物理地址,这样操作系统可以隔离不同进程的地址空间,保证进程之间不会相互干扰。
页表结构
xv6 基于 Sv39 RISC-V,所以只用了 64 位虚拟地址的后 39 位。这 39 位中的前 27 位用于索引页表,后 12 位用于索引页内偏移。所以每页的大小是 \(2^{12}=4096\) 字节。
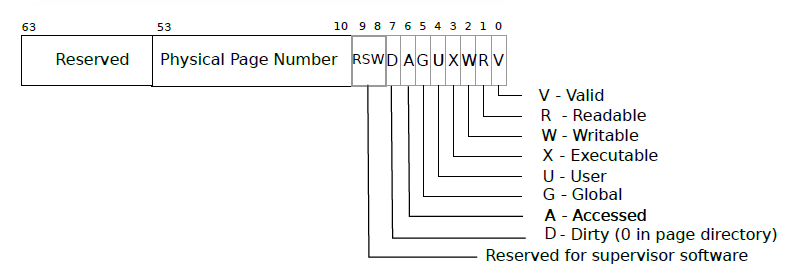
xv6 的页表逻辑上是一个 \(2^{27}\) 的数组,每个数组元素是一个页表项 PTE (Page Table Entry)。下图展示了 PTE 的结构。
PTE 的低 10 位是标志位,标识 PTE 的状态和权限。如 PTE_V 控制页面是否有效,PTE_R 控制页面是否可读,PTE_W 控制页面是否可写,PTE_X 页面内容是否可解释为指令执行。PTE_U 控制用户模式下的指令是否可以访问这个页面等。
PTE 的 11 位到 54 位是物理页号 PPN (Physical Page Number),用于指向物理内存中的页。剩下的 10 位是保留位,用于以后扩展页表的功能。
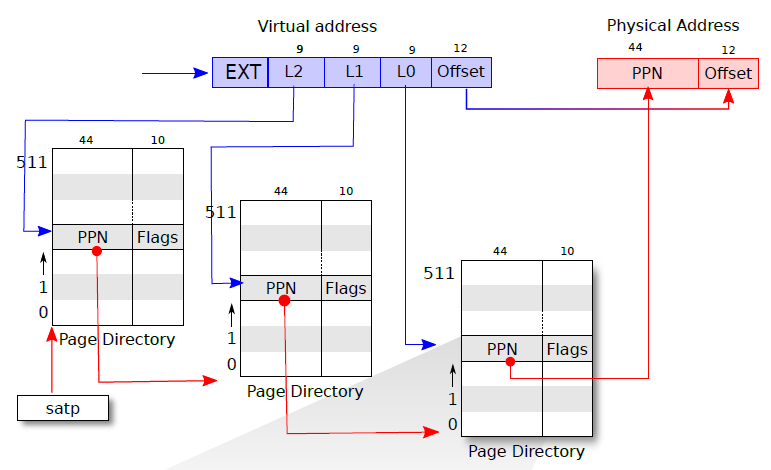
xv6 采用三级页表,每级有 512 个 PTE,结构如下图所示。最后一级指向物理内存的页表条目称为叶子节点,前两级的称为非叶子节点。非叶子节点仅 PTE_V 标志位有效,其他标志位为 0。
虚拟地址的页表索引被分为三部分,分别用于索引三级页表。其中根页表的物理地址是保存在 CPU 的 satp 寄存器中。通过 L2 可以索引到根页表的 PTE 得到 PPN,在 PNN 后加上 12 位 0 即为第二级页表的物理地址。同样地,可通过 L1 索引到第二级页表中的 PTE,进而得到第三级页表的物理地址。第三级页表的 PTE 中的 PPN 就是虚拟地址对应的物理页号,将这个物理页号和偏移量组合起来即可得到对应的物理地址。
使用多级页表的好处是可以节省内存。假设一个进程只用了一页内存,在使用单级页表的情况下,页表大小是 \(2^{27}\) 个 PTE,即 \(2^{27}\times8\mathrm{B}=1\mathrm{GB}\) 。
而使用三级页表的情况下,首先需要一个一级页表,其中只有一个有效 PTE,所以只给这个 PTE 创建二级页表。二级页表中也只有一个有效 PTE,只给它创建三级页表。这样总共只有三个页表,一个页表的大小是 \(2^{9}\times8\mathrm{B}=4\mathrm{KB}\) ,所以总共只需要 \(3\times4\mathrm{KB}=12\mathrm{KB}\) 的内存。
多级页表的缺点是将虚拟地址到物理地址需要多次转换,计算开销较大。为解决这个问题,CPU 中有一个 TLB (Translation Lookaside Buffer) 缓存最近的虚拟地址到物理地址的映射。
内核地址空间
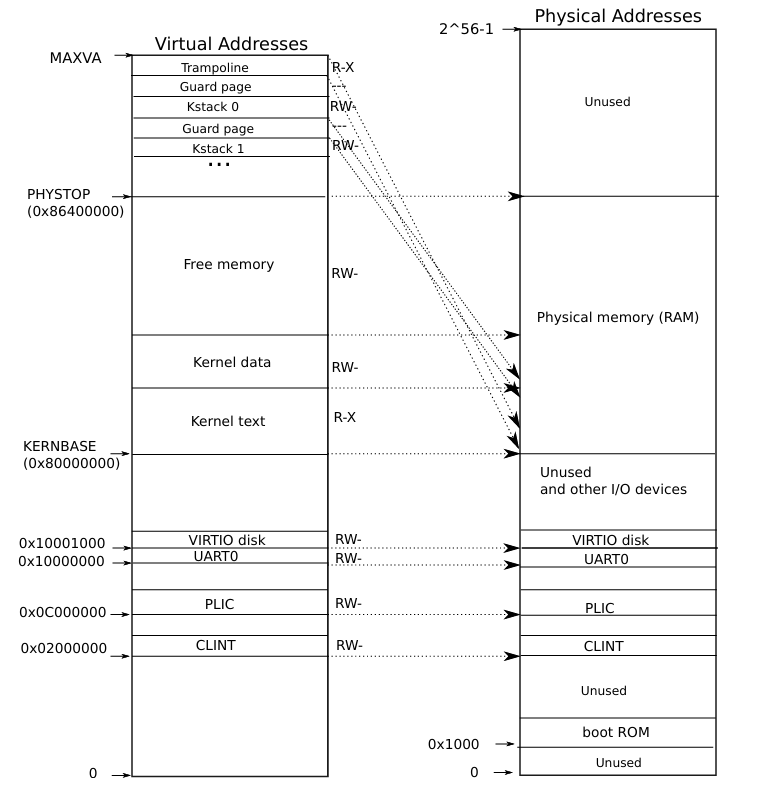
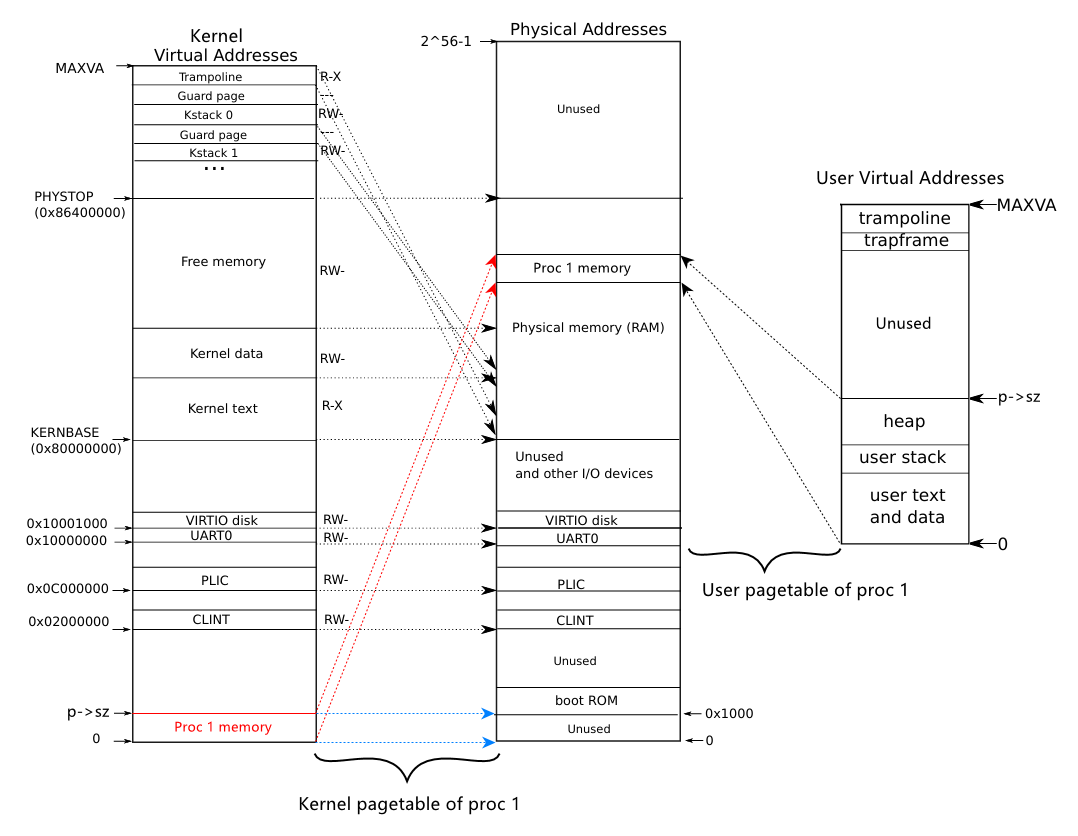
上图在后文中会多次提到,后文称此图为 “内核空间图”。图中左侧是内核的虚拟地址空间,右侧是物理地址空间。内存空间从物理地址的 0x80000000 开始,在此之前的空间是其他 IO 设备的映射。内核使用直接映射的方式,将虚拟地址映射到物理地址。但也有些虚拟地址是不映射到物理地址的,如 TRAMPOLINE 和内核栈被映射到虚拟地址的高位,这是为了避免内核栈溢出时覆盖其他内核数据。内核栈之间的无效的保护页也是这个作用。
用户地址空间
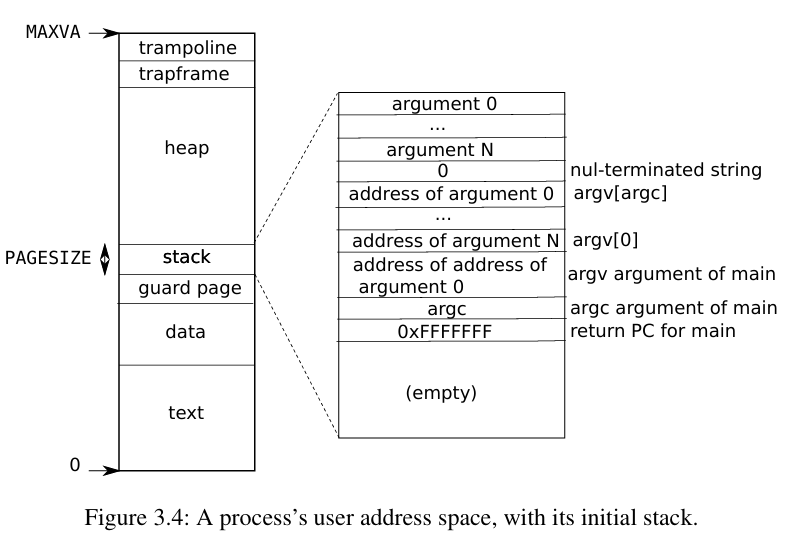
上图展示了用户进程的虚拟地址空间。每个用户进程的虚拟地址都从 0 开始,最大可到 MAXVA。和内核地址空间一样,用户地址空间的最高处也有一个 TRAMPOLINE 页面,所以在所有地址空间中都可以访问相同的 TRAMPOLINE 页面。用户栈的下方同样有一个无效的保护页,用于保护栈的下方不被覆盖。
源码阅读
理解 xv6 中页表相关源码对本次 Lab 非常重要。
memlayout.hmemlayout.h 定义了 xv6 的内存布局相关的宏,即上面内核空间图中的地址。比较重要的是下面几个宏定义。
1 2 3 4 5 6 7 8 9 #define KERNBASE 0x80000000L #define PHYSTOP (KERNBASE + 128*1024*1024) #define TRAMPOLINE (MAXVA - PGSIZE) #define KSTACK(p) (TRAMPOLINE - ((p)+1)* 2*PGSIZE)
riscv.h定义了读写 CPU 寄存器的函数和页表相关的类型和宏。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #define PGSIZE 4096 #define PGSHIFT 12 #define PGROUNDUP(sz) (((sz)+PGSIZE-1) & ~(PGSIZE-1)) #define PGROUNDDOWN(a) (((a)) & ~(PGSIZE-1)) #define PTE_V (1L << 0) #define PTE_R (1L << 1) #define PTE_W (1L << 2) #define PTE_X (1L << 3) #define PTE_U (1L << 4) #define PA2PTE(pa) ((((uint64)pa) >> 12) << 10) #define PTE2PA(pte) (((pte) >> 10) << 12) #define PTE_FLAGS(pte) ((pte) & 0x3FF) #define PXMASK 0x1FF #define PXSHIFT(level) (PGSHIFT+(9*(level))) #define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK) #define MAXVA (1L << (9 + 9 + 9 + 12 - 1)) typedef uint64 pte_t ; typedef uint64 *pagetable_t ;
vm.cvm.c 用于管理虚拟内存,实现了页表的创建、映射、解除映射等功能。以 kvm 开头的函数操作内核空间,uvm 开头的操作用户空间。
walk 和 mappages 是两个非常关键的函数,其他大部分函数都是基于这两个函数实现的。
walk 函数的作用是在页表 pagetable 中找到虚拟地址 va 对应的最后一级页表中 PTE 的地址。如果 alloc 不为 0,则在查找中遇到无效页表时将其分配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 pte_t *walk (pagetable_t pagetable, uint64 va, int alloc) if (va >= MAXVA)"walk" );for (int level = 2 ; level > 0 ; level--) {pte_t *pte = &pagetable[PX(level, va)];if (*pte & PTE_V) {pagetable_t )PTE2PA(*pte);else {if (!alloc || (pagetable = (pde_t *)kalloc()) == 0 )return 0 ;memset (pagetable, 0 , PGSIZE);return &pagetable[PX(0 , va)];
mappages 函数在页表 pagetable 中创建总大小近似为 size 的若干页面,并设置这些页的权限为 perm。第一个页面的虚拟地址 va 映射到物理地址 pa。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int mappages (pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm) pte_t *pte;1 );for (;;){if ((pte = walk(pagetable, a, 1 )) == 0 )return -1 ;if (*pte & PTE_V)"remap" );if (a == last)break ;return 0 ;
kvmmap 是 mappages 的包装,用于添加内核页表的映射。
kvminit 函数用于初始化内核页表,将内核的虚拟地址映射到物理地址。该函数完成了内核空间图中除内核栈以外的其他映射。
kvminithart 向 CPU 的 satp 寄存器中写入内核页表的物理地址,并刷新 TLB。初次调用此函数时就启用了分页,在此之后 CPU 指令中的地址全部被视为虚拟地址。
保证这一转换前后正确的关键是虚拟地址是物理地址的直接映射。实际上,walk 函数也利用了直接映射的特点,PTE 中的 PPN 是物理地址,但是在 walk 函数中被当作虚拟地址处理。
1 2 3 4 5 6 void kvminithart ()
uvmunmap 函数用于解除从虚拟地址 va 开始的 npages 个页面的映射。如果 do_free 为 1,则释放这些页面对应的物理内存。
uvmcreate 函数为用户程序创建了一个新页表。uvmalloc 将页表的大小从旧的大小增加到新的大小,uvmdealloc 则是释放页表的内存。
freewalk 用于删除页表 pagetable。调用此函数之前页表的叶子节点必须已经被解除映射 (有效位为 0)。
walkaddr 包装了 walk 函数,添加了对虚拟地址的合法性检查,用于将指定页表的虚拟地址转换为物理地址。
kalloc.ckalloc.c 用于管理物理内存,实现了物理内存的分配和释放。
物理内存块是用 run 结构体表示的,实际上是一个链表节点。每块大小为 PGSIZE,即 4096 字节。
kmem 维护了一个空闲内存块的链表,kmem.freelist 指向链表的头节点。还有一个自旋锁 kmem.lock 用于保护 freelist。
kfree 函数释放一个物理内存块,使用头插法将其插入到空闲内存块链表的头部。
kalloc 函数分配一个物理内存块,从空闲内存块链表的头部取出一个节点,返回指向它的指针。这个指针的值是物理地址。
题解
Print a page table (easy)
本题要求编写一个打印页表的函数 vmprint,示例输出如下,.. 的个数代表 pte 的层级。
1 2 3 4 5 6 7 8 9 10 page table 0x0000000087f6e000
思路
实现代码
kernel/vm.c 中新增以下函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void vmprint_recursive (pagetable_t pagetable, int level) {for (int i = 0 ; i < 512 ; i++) {pte_t pte = pagetable[i];if (pte & PTE_V) {for (int j = 0 ; j < level; j++) {printf (".. " );printf ("..%d: pte %p pa %p\n" , i, pte, child);if ((pte & (PTE_R|PTE_W|PTE_X)) == 0 )pagetable_t )child, level + 1 );void vmprint (pagetable_t pagetable) {printf ("page table %p\n" , pagetable); 0 );
kernel/defs.h 中新增 vmprint 函数的声明。
1 2 void vmprint (pagetable_t pagetable) ;
kernel/exec.c 中 exec 函数的 return argc; 前加上以下代码:
1 2 3 4 5 6 if (proc->pid == 1 ) {return argc;
A kernel page table per process (hard)
本题要求为每个进程创建一个内核页表,使得每个进程都有自己的内核地址空间。进程的内核页表除了内核栈外,其他映射和全局内核页表的内容一致。
提示
在 struct proc 中添加一个字段,用于存储进程的内核页表。
一个为新进程生成内核页表的合理方法是实现一个修改版的 kvminit,该函数创建一个新的页表而不是修改 kernel_pagetable。你需要在 allocproc 中调用这个函数。
确保每个进程的内核页表都有一个映射到该进程内核栈的映射。在未修改的 xv6 中,所有的内核栈都在 procinit 中设置。你需要将部分或全部功能移动到 allocproc 中。
修改 scheduler() 以将进程的内核页表加载到核心的 satp 寄存器中(参见 kvminithart 获取灵感)。在调用 w_satp() 之后不要忘记调用 sfence_vma()。
当没有进程运行时,scheduler() 应该使用 kernel_pagetable。
在 freeproc 中释放进程的内核页表。
你需要一种方法来释放页表而不释放叶子物理内存页。
vmprint 可能对调试页表有帮助。可以修改 xv6 函数或添加新函数;你可能需要在 kernel/vm.c 和 kernel/proc.c 中执行此操作。(但是,不要修改 kernel/vmcopyin.c、kernel/stats.c、user/usertests.c 和 user/stats.c。)
缺少页表映射可能会导致内核遇到页面错误。它会打印一个包含 sepc=0x00000000XXXXXXXX 的错误。你可以通过在 kernel/kernel.asm 中搜索 XXXXXXXX 来找出错误发生的位置。
实现代码
题中给的提示已经比较详细了,按照提示一步步实现。个人认为难点主要是代码修改的地方较多,出错了不好排错。下面给出实现步骤:
在 proc.h 中添加进程的内核页表字段。
1 2 3 4 5 6 7 8 9 10 struct proc {pagetable_t pagetable; pagetable_t kpagetable;
在 vm.c 中参考 kvminit 和 uvmcreate 实现一个新函数用于创建进程的内核页表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 pagetable_t ukvminit () pagetable_t pagetable;pagetable_t ) kalloc();if (pagetable == 0 ) {return 0 ;memset (pagetable, 0 , PGSIZE);0x10000 , PTE_R | PTE_W);0x400000 , PTE_R | PTE_W);return pagetable;
然后在 proc.c 的 allocproc 函数中调用 ukvminit 函数,位置可以在用户页表的初始化之后。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static struct proc*allocproc (void ) if (p->pagetable == 0 ){return 0 ;if (p->kpagetable == 0 ){return 0 ;
创建进程的内核页表后需要为其分配内核栈,原来的内核栈分配在 procinit 中,现在需要将其移动到 allocproc 中,就是上面一步的代码之后。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static struct proc*allocproc (void ) if (p->kpagetable == 0 ){return 0 ;char *pa = kalloc();if (pa == 0 )"kalloc" );0 );
注意原来一个内核页表要包含所有进程的内核栈,所以原代码映射内核栈用的是 KSTACK(p-proc)。修改后只需在每个进程自己的内核页表中映射自己的内核栈即可,所以这里改为了 KSTACK(0)。同时将原来映射用的 kvmmap 改为了 ukvmmap,这个函数仿照 kvmmap 实现即可。
1 2 3 4 5 6 7 void ukvmmap (pagetable_t pagetable, uint64 va, uint64 pa, uint64 sz, int perm) if (mappages(pagetable, va, sz, pa, perm) != 0 )"ukvmmap" );
内核栈的改动会影响 vm.c 中的 kvmpa 函数,将其中 walk 函数中的 kernel_pagetable 改为 myproc()->kpagetable。不要忘了加上两个头文件的引用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include "spinlock.h" #include "proc.h" kvmpa (uint64 va) pte_t *pte;0 );
在 CPU 切换进程时,需要将进程的内核页表加载到 satp 寄存器中,仿照 kvminithart 修改 scheduler 函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void scheduler (void ) if (p->state == RUNNABLE) {0 ;1 ;
最后在添加释放进程的内核页表的代码,仿照 proc_freepagetable 实现 proc_freekpagetable 函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static void freeproc (struct proc *p) if (p->pagetable)if (p->kpagetable)0 ;0 ;0 ;void proc_freekpagetable (pagetable_t pagetable) 0 ), 1 , 1 );
释放进程的内核页表不需要释放对应的物理内存,所以只需将页表项全部置为 0,再释放页表的内存即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void ukvmfree (pagetable_t pagetable) for (int i = 0 ; i < 512 ; i++) {pte_t pte = pagetable[i];if (pte & PTE_V) {0 ;if ((pte & (PTE_R|PTE_W|PTE_X)) == 0 )pagetable_t )PTE2PA(pte));void *)pagetable);
最后不要忘记在 defs.h 中声明新增的函数。
1 2 3 4 5 6 7 8 void proc_freekpagetable (pagetable_t ) ;pagetable_t ukvminit () ;void ukvmmap (pagetable_t pagetable, uint64 va, uint64 pa, uint64 sz, int perm) ;void ukvmfree (pagetable_t pagetable) ;
Simplify copyin/copystr (hard)
本题要求简化 copyin 和 copystr 函数,用 copyin_new 和 copystr_new 替换其实现。
原来这两个函数需要将用户虚拟地址转换为物理地址来获取用户空间的数据,新的实现中它们能直接使用用户虚拟地址访问相应数据。我们需要保证这个替换能够正常工作。
思路
对比以下两个函数,弄清楚下面几个问题:
为什么原来内核不能直接解引用用户空间的指针?
memmove 函数操作的是物理地址还是虚拟地址?怎样让内核通过用户虚拟地址正确访问对应的数据?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int copyin (pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) while (len > 0 ){if (pa0 == 0 )return -1 ;if (n > len)void *)(pa0 + (srcva - va0)), n);return 0 ;
1 2 3 4 5 6 7 8 9 10 11 int copyin_new (pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) struct proc *p =if (srcva >= p->sz || srcva+len >= p->sz || srcva+len < srcva)return -1 ;void *) dst, (void *)srcva, len);return 0 ;
先来思考第二个问题。memmove 在 copyin 中好像操作的是物理地址,而在 copyin_new 中又似乎操作的是虚拟地址。这让人有点迷惑,如果 memmove 既能操作物理地址又能操作虚拟地址,那么是什么来决定它的行为呢?memmove 的实现中都是对指针进行操作,似乎它并不关心指针指向的是物理地址还是虚拟地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void *memmove (void *dst, const void *src, uint n) const char *s;char *d;if (s < d && s + n > d){while (n-- > 0 )else while (n-- > 0 )return dst;
让我们回想一下本次 Lab 的主题:页表。没错,就是页表决定了 memmove 的行为。准确地说是 satp 寄存器中的页表规定了内存管理单元 MMU 该如何解释 CPU 指令中的地址,进而决定了代码中的指针的含义。实际上,在 copyin 和 copyin_new 中的都是虚拟地址,只是前者使用的内核页表将大多数虚拟地址直接映射到物理地址,所以我们直接按照物理地址来理解了。
第一个和第三个问题可以用下面这张图来解释。假设有一个进程 proc 1,它所用内存的物理空间是在 Free memory 部分分配的,内存大小为 p->sz。它的用户页表将虚拟地址 0 和 p->sz 分别映射到进程所用物理内存的最低地址和最高地址,就像下图的右半部分展示的那样。
在内核空间运行时中启用的是内核页表,但在内核页表中虚拟地址基本都是直接映射到物理地址的,所以用户的虚拟地址会被映射到错误的地方,如下图左半部分蓝色箭头所示。我们的目标就是修改进程的内核页表,让这一部分虚拟地址映射到正确的位置。
实现代码
首先把 copyin 和 copyinstr 函数中的实现替换为对 copyin_new 和 copyinstr_new 的调用。
1 2 3 4 5 6 7 8 9 10 11 12 int copyin (pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) return copyin_new(pagetable, dst, srcva, len);int copyinstr (pagetable_t pagetable, char *dst, uint64 srcva, uint64 max) return copyinstr_new(pagetable, dst, srcva, max);
由于内核启动后,地址空间中 PLIC 以下的地址都是无用的,所以只要在用户页表变化时,内核页表也同步变化即可。
At each point where the kernel changes a process's user mappings, change the process's kernel page table in the same way. Such points include fork(), exec(), and sbrk().
不过题中提示中的表述可能会让人一开始想到的是在每一处修改用户页表时用同样的操作更改内核页表,这样太繁琐而且容易出错。我们直接在每次用户页表完成所有修改后复制用户页表项到内核页表就可以了,并且采用增量修改的方式,只处理变化的部分。
在 vm.c 中添加下面两个函数,ukvmcopy 是仿照 uvmcopy 实现的,用于复制用户页表的变化到内核页表;ukvmdealloc 则参考了 uvmdealloc,用于解除内核页表的映射。
在 ukvmcopy 函数中,需要将 PTE_U 位清除,使内核可以访问对应数据。在 ukvmdealloc 函数中,只要将 PTE 的有效位清除即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void ukvmcopy (pagetable_t user, pagetable_t kernel, uint64 oldsz, uint64 newsz) {pte_t *pte, *kpte;for (va = oldsz; va < newsz; va += PGSIZE){if ((pte = walk(user, va, 0 )) == 0 )"ukvmcopy: pte should exist" );if ((*pte & PTE_V) == 0 )"ukvmcopy: page not present" );if ((kpte = walk(kernel, va, 1 )) == 0 )"ukvmcopy: walk fail" );void ukvmdealloc (pagetable_t pagetable, uint64 oldsz, uint64 newsz) {if (newsz >= oldsz)return ;pte_t *pte;if (PGROUNDUP(newsz) < PGROUNDUP(oldsz)){for (va = PGROUNDUP(newsz); va < PGROUNDUP(oldsz); va += PGSIZE)if ((pte = walk(pagetable, va, 0 )) == 0 )"ukvmdealloc: walk" );
在修改用户页表的位置添加上面的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int exec (char *path, char **argv) {0 , p->sz);
在 growproc 函数中需要添加对用户内存空间的限制,不能超过 PLIC。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 void userinit (void ) sizeof (initcode));0 , p->sz);int growproc (int n) struct proc *p =if (n > 0 ){if (sz + n > PLIC)return -1 ;if ((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0 ) {return -1 ;else if (n < 0 ){return 0 ;int fork (void ) if (uvmcopy(p->pagetable, np->pagetable, p->sz) < 0 ){return -1 ;0 , np->sz);
最后在 defs.h 中声明新增的函数。
1 2 3 4 5 6 void ukvmcopy (pagetable_t user, pagetable_t kernel, uint64 oldsz, uint64 newsz) ;void ukvmdealloc (pagetable_t pagetable, uint64 oldsz, uint64 newsz) ;int copyin_new (pagetable_t pagetable, char *dst, uint64 srcva, uint64 len) ;int copyinstr_new (pagetable_t pagetable, char *dst, uint64 srcva, uint64 max) ;
总结
页表规定了虚拟地址到物理地址的映射关系,内核和进程都有自己的页表。
多级页表可以节省内存空间,但是会增加查询的开销。使用 TLB 缓存可以缓解这个问题。
内核页表将大多数虚拟地址直接映射到物理地址,所以在部分函数中直接把内核的虚拟地址当作物理地址来理解了。
一个地址具体该如何解释取决于 satp 寄存器中的页表。
xv6 内核地址空间和用户地址空间的结构。
本次 Lab 的难度较大,需要对页表的机制有较深的理解,还要掌握页表在 xv6 中的实现方式。做这个 Lab 花了不少时间,但收获也是很多的。